Implementing In-Context Learning in a Custom Environment
Oviya Seeniraj, Gary Shen, Mihir Kachroo
Can agents learn from past successes? We added a trajectory bank and few-shot learning. Same tasks, same models — but agents now receive demonstrations from prior wins. Here's what happened.
Prev. in series: RL agents in a food-order environment
Benchmarking AI Agents using RL Environments
Can non-deterministic systems arrive at deterministic solutions? We present our findings after evaluating frontier AI models across 180 episodes in our custom RL environment.
Intro
In our first post, we tested top AI models in a food-ordering environment without giving them any prior examples. They couldn’t learn from past mistakes or successes. This raised a key question: could performance improve if agents were allowed to learn from previous runs?
In this blog, we explore in-context learning (ICL)—improving agent behavior without updating model weights, simply by providing better context at inference time. We intentionally chose ICL over supervised fine-tuning (SFT), since in real-world practice, fine-tuning flagship models is often impractical, costly, and frequently unnecessary.
To test this, we built a lightweight few-shot learning loop: successful task completions are stored, indexed, and surfaced as demonstrations before the agent tackles a new task.
We then reran the same benchmark from our first post in the same environment (10 tasks, 3 runs per model). This post answers a central question: can ICL improve frontier agents—and where does it fall short?
The Learning Loop
At a high level, the system has four parts that form a loop:
- Past successes — We collect successful task completions (right store, right items, best discount applied).
- Knowledge bank — These are indexed by task similarity so we can retrieve relevant examples.
- Agent — Before acting, the agent receives one or two similar successful demonstrations in its prompt.
- Environment — The agent then acts on the live task. New successes feed back into the bank.

Same agent, same environment — the only change from baseline to few-shot is that we add context from previous similar runs to the prompt.
The key idea: demonstrations teach correctness, not just completion. Zero-shot agents often finish the workflow (place an order) but get details wrong — wrong store, suboptimal discount, missing add-on. Showing them how someone solved a similar task addresses those failure modes.
Observations & Results
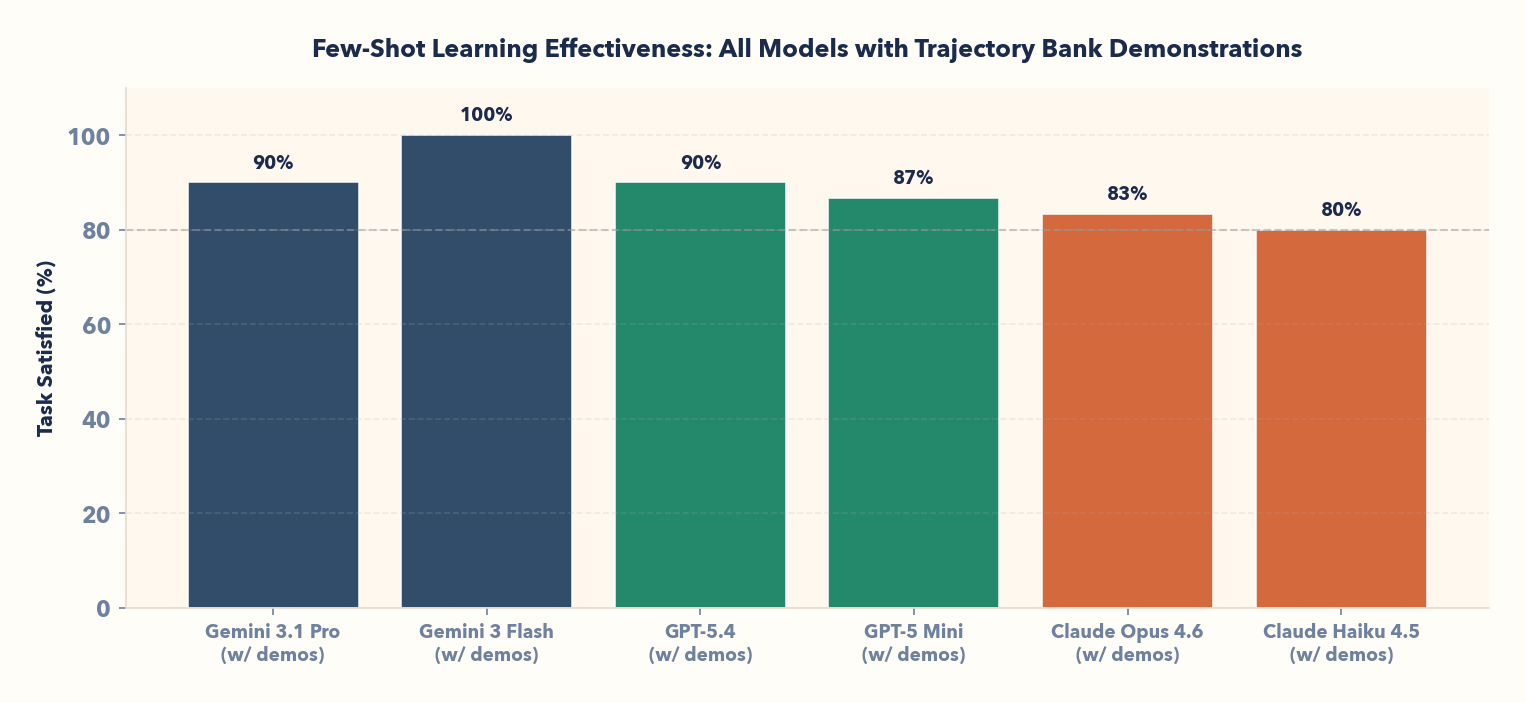
We ran the benchmark with 3 runs × 10 tasks per model = 30 baseline and 30 in-context episodes each. Here are our results:
📌 Note
TC = Task Completed. Agents completed SOME order and arrived at SOME end state, regardless of correctness.
TS = Task Satisfied. Agents completed the order CORRECTLY, with right store/items/discount.
| Model | Provider | BaseLINE TC | BaseLINE TS | ICL TC | ICL TS |
|---|---|---|---|---|---|
| Gemini 3.1 Pro | 93% (28/30) | 90% (27/30) | 90% (27/30) | 90% (27/30) | |
| GPT-5.4 | OpenAI | 57% (17/30) | 43% (13/30) | 97% (29/30) | 90% (27/30) |
| GPT-5 Mini | OpenAI | 60% (18/30) | 33% (10/30) | 93% (28/30) | 87% (26/30) |
| Gemini 3 Flash | 100% (30/30) | 80% (24/30) | 100% (30/30) | 100% (30/30) | |
| Claude Opus 4.6 | Anthropic | 90% (27/30) | 80% (24/30) | 93% (28/30) | 83% (25/30) |
| Claude Haiku 4.5 | Anthropic | 87% (26/30) | 23% (7/30) | 93% (28/30) | 80% (24/30) |
The gap between task completion and correctness — and the changes from baseline to ICL — is the story.
I. Frontier models learn prudence: Abstention is a feature, not a bug
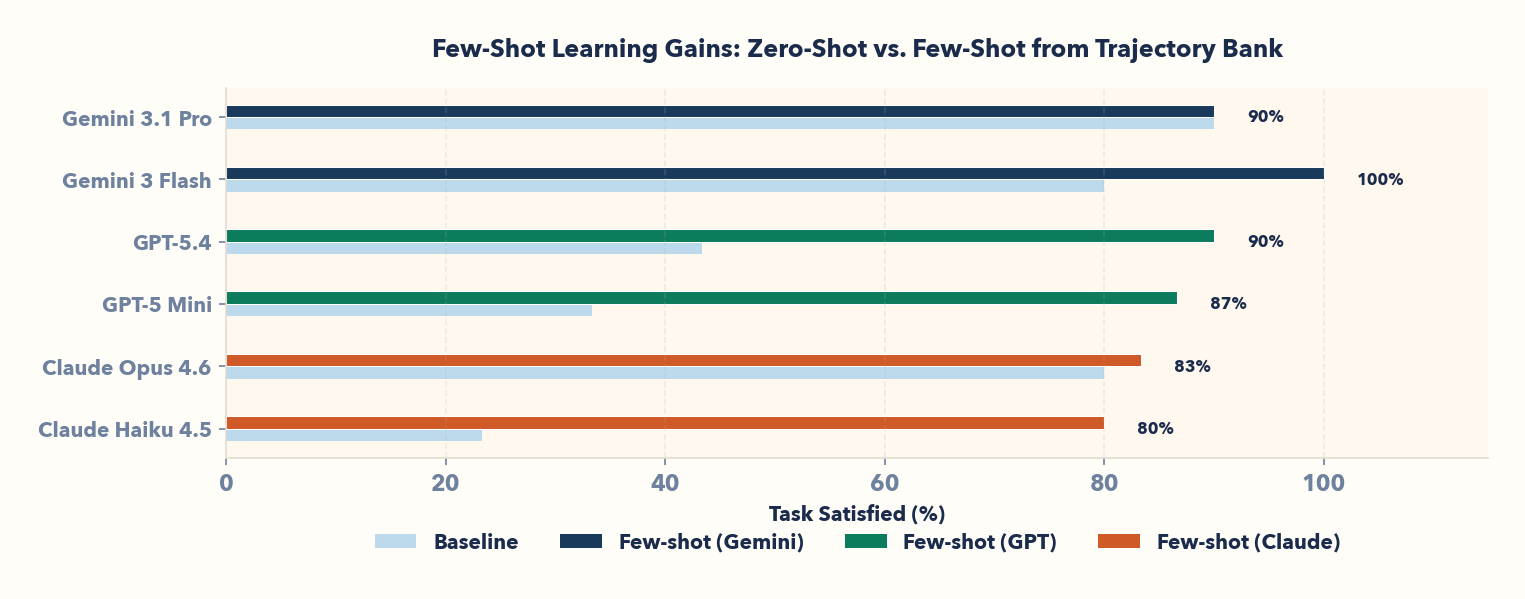
Gemini 3.1 Pro baseline: 90% task satisfied. Gemini 3.1 Pro ICL: 90% task satisfied (no change in correctness).
But look at action completion: it drops from 93% to 90% (−3 points). This is not a regression—it's learned calibration. Demonstrations taught the model to abstain: when it's unsure, it skips the action rather than confidently complete an incorrect order.
Zero-shot, Gemini 3.1 Pro completes 93% of workflows—but some are wrong. Few-shot, it completes 90%—and all of them are correct. This abstention was not a failure: it was a learned strategy to reduce hallucination.
🔍 General Pattern
In-context learning like few-shot allows agents to learn to trade raw completion for accuracy, reducing hallucinated orders.
II. Smaller models gain most from demonstrations; scaling down becomes practical
Claude Haiku gains +17 points, GPT-5 Mini +16 points, GPT-5.4 +14 points. The pattern holds: models with the largest baseline gaps gain the most from few-shot.
This has a practical implication: cheap models get significantly smarter when given the right examples. Claude Haiku at 80% ICL task satisfaction is competitive with Claude Opus at 83% baseline—without fine-tuning. GPT-5 Mini at 87% rivals frontier models' zero-shot performance.
The trajectory bank acts as a knowledge transfer mechanism: expensive models' successes lift cheaper models to comparable performance levels.
🔍 General Pattern
Few-shot learning gains can help compact models (Claude Haiku, GPT Mini, and Gemini Flash) achieve flagship model (Opus, Pro) accuracy -- a huge cost and compute win if explored correctly.
III. Few-shot dramatically improves smaller models; ceiling effects for frontier
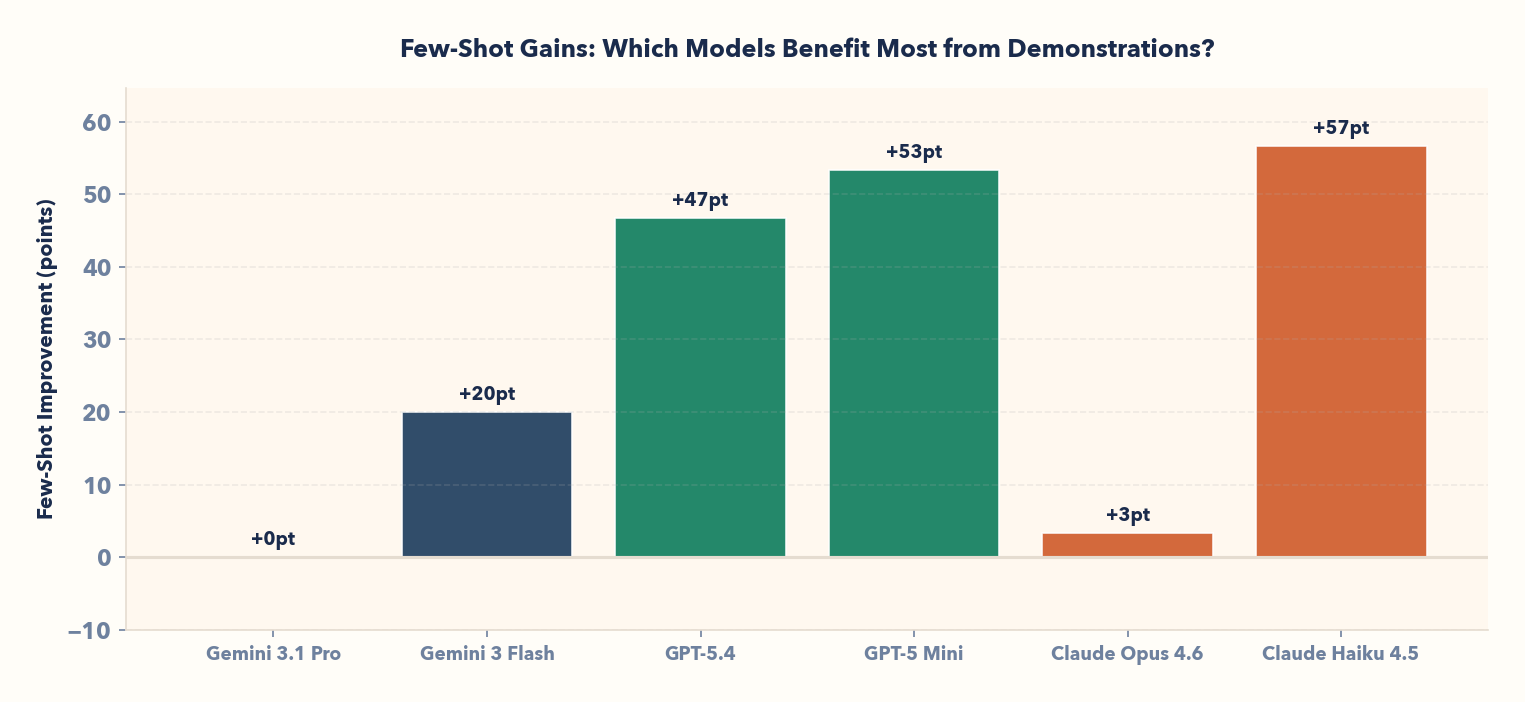
Claude Haiku 4.5: 23% baseline → 80% few-shot (+17 points). GPT-5 Mini: 33% → 87% (+16 points). GPT-5.4: 43% → 90% (+14 points).
All three close the correctness gap significantly.
In contrast, Gemini 3.1 Pro—already at 90% baseline—shows no improvement. Claude Opus 4.6 moves from 80% to 83% (+3 points). The pattern is clear: few-shot helps where zero-shot leaves room for improvement; at the ceiling (high-performance models), demonstrations offer no benefit.
🔍 General Pattern
In-context learning in this case is most effective on compact or lower-performing models, where it drives substantial gains, while flagship models show little to no improvement.
IV. Simply put, in-context learning works without fine-tuning
We don’t modify model weights—the entire learning signal lives in the prompt. By showing agents similar successful runs before they act, we keep the system lightweight and easy to reproduce. The tradeoff is that improvements are purely in-context: cold-start performance doesn’t improve, and we remain constrained by limited context windows.
🔍 General Pattern
Few-shot from a trajectory bank proves learning improves agentic workflows, but does not have permanent effects.
Next Steps
1. Higher impact environments -- scaling up to longer horizons and enterprise workflows
Today, AI agents are increasingly used to automate multi-application workflows. We will now extend our environment-based benchmarking approach to complex, multi-step, multi-agent enterprise workflows (Slack, Jira, Gmail, Workday, etc.) to evaluate real-world impact.
2. Creating dynamic, self-generating environments
Environments can reveal a wide range of agent failure modes, but their effectiveness depends on the quality of the environment and task bank—both of which are highly specific to each agent. To address this, we are moving toward adversarially generated tasks and environments, enabling automated, intelligent stress-testing through Unsupervised Environment Design (UED).
Stay tuned: our next blog reveals the evaluation results when UED methodologies are brought to high-impact enterprise environments.
Recap:
- The thesis: Agents can learn from past successes with ICL, without any fine-tuning.
- Results: A trajectory bank + few-shot proves it across all frontier and mid-tier models. Flagship models train out hallucinations while smaller models reach baseline frontier level performance.
Interested in our work, access to this experiment, or looking to collaborate? Reach us at [email protected].