Benchmarking AI Agents using RL Environments
Oviya Seeniraj, Gary Shen, Mihir Kachroo
Can non-deterministic systems arrive at deterministic solutions? We present our findings after evaluating frontier AI models across 180 episodes in our custom RL environment.
Intro
The promise of AI agents is alluring: systems that assess their environment, plan, and execute multi-step workflows autonomously. Infinitely scalable productivity, in theory.
But can they arrive at a deterministically correct solution as an inherently non-deterministic system? That's what RL environments test. Broadly, agents reason (LLM inference), recall (memory retrieval), and act (tool calls).
The LLM reasoning capabilities of agent 'brains' have been heavily tested, benchmarked, and evaluated. However, to test the entire modern agentic workflow, we need to test if agents can correctly take actions to execute their planned workflows.
This is what we do in our custom environment -- we provide actions for agents to take, following which we verify if they take the correct chain of actions to arrive at the deterministic end state. Each action returns a state and reward, with a final binary verdict per task.
Our goal: Benchmark frontier lab models on our new RL environment and see how they perform. Spoiler: the gap between "finished" and "correct" is enormous.
📌 Note
This post is the first in a series. Here, we benchmark, evaluate, and analyze results. In our next post, we share post-training results.
The Environment We Built
At a high level, the environment has three parts:
I. A World of Constrained Tasks
A world that gives agents tasks requiring reasoning under constraints: not just simple retrievals, but augmented, multi-step problems.
II. A Defined Action Space
A defined action space that allows the agent to interact with and evaluate the world, enabling them to complete tasks and us to assess their abilities:
💡 Insight
As is convention, each action maps to a state and reward. (The names above are environment-specific; they generalize to search, select, apply, commit, and observe primitives in any RL setup). We also add evaluation notes.
III. A Verifier
A verifier determines the ground-truth solution and evaluates two outcomes:
- action completed: the agent reaches a terminal state (wrong outcome = '0', same as incomplete)
- task satisfied: the agent reaches the correct terminal state (the actual solution = '1')
Our workflow:
- Natural-Language Task: The agent receives a task in plain English. Example: "Order Beef Kebab Platter and Ayran from Shawarma House and apply best discount."
- Environment Loaded: A live web app is launched, and the agent is initialized with the task and the current app state (menus, prices, cart, etc.).
- Agent Reasons: The agent observes the environment and decides what to do next, considering available items, prices, coupons, and cart state.
- Agent Executes on Live App: The agent takes real actions in the app, such as searching stores, adding items to cart, applying discounts, and checking out.
- Scoring & Feedback Loop: Each action is evaluated with positive reward for progress and penalties for mistakes. The agent can loop (up to ~20 steps) to improve its outcome or terminate.
- Binary Verdict (Pass/Fail): The system checks whether the agent satisfied all constraints, including right store, correct items, and best discount. Result:
0or1(fail or pass). No partial credit. - Everything Logged: The full episode is recorded, including actions taken, state transitions, model reasoning, and final evaluation.
Observations & Key Takeaways
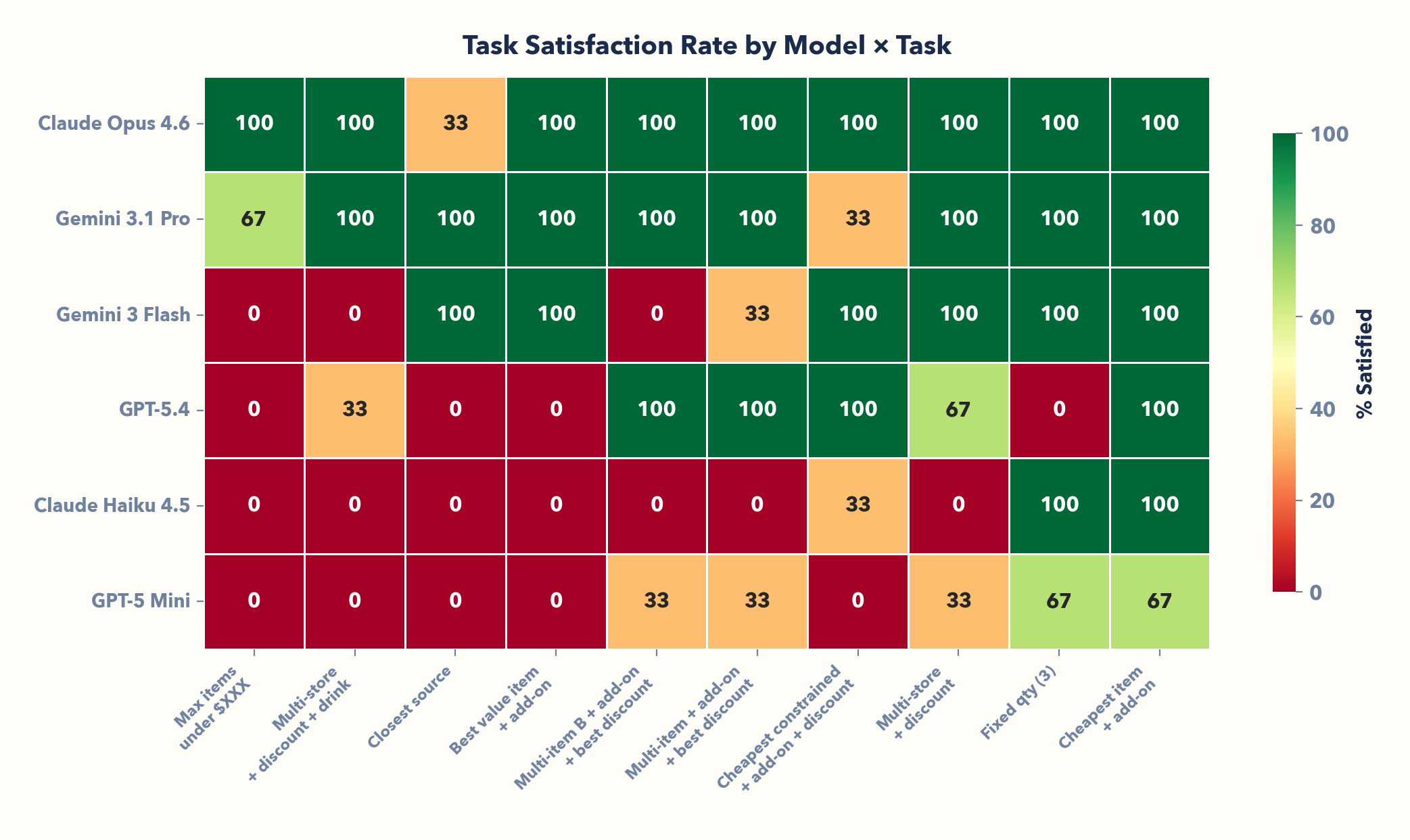
10 tasks, 6 models, three frontier labs (Anthropic, OpenAI, Google) — 180 episodes. Same environment, same tools. Here's what happened:
| Model | Provider | Runs | Episodes | Task Satisfied | Action Completed |
|---|---|---|---|---|---|
| Claude Opus 4.6 | Anthropic | 3 | 30 | 93% (28/30) | 93% (28/30) |
| Gemini 3.1 Pro | 3 | 30 | 90% (27/30) | 90% (27/30) | |
| Gemini 3 Flash | 3 | 30 | 63% (19/30) | 90% (27/30) | |
| GPT-5.4 | OpenAI | 3 | 30 | 50% (15/30) | 63% (19/30) |
| Claude Haiku 4.5 | Anthropic | 3 | 30 | 23% (7/30) | 83% (25/30) |
| GPT-5 Mini | OpenAI | 3 | 30 | 23% (7/30) | 50% (15/30) |
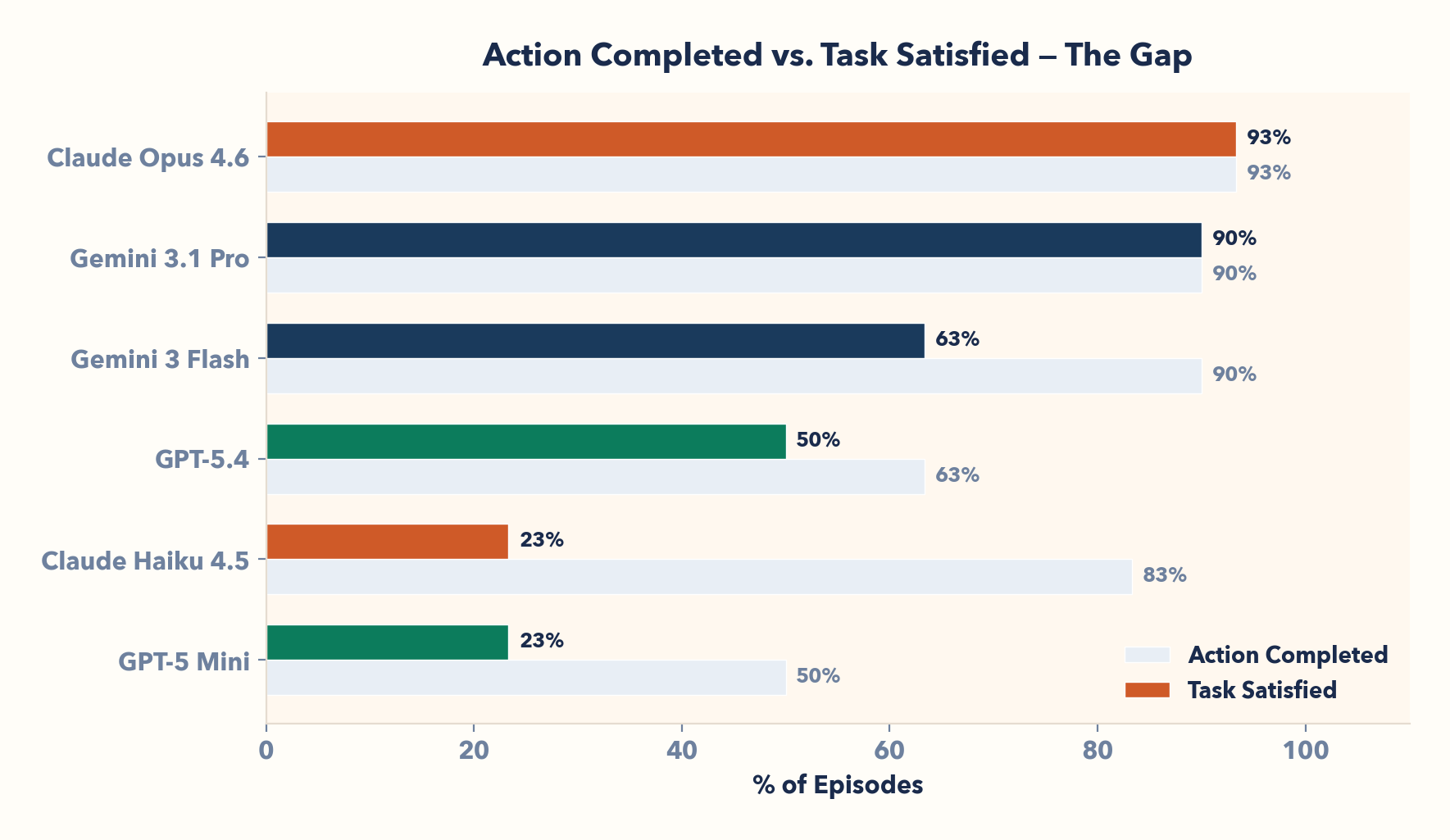
Models that complete workflows aren't necessarily completing them correctly. The gap between Action Completed and Task Satisfied reveals how often agents confidently reach the wrong answer.
I. Completing a workflow ≠ completing it correctly
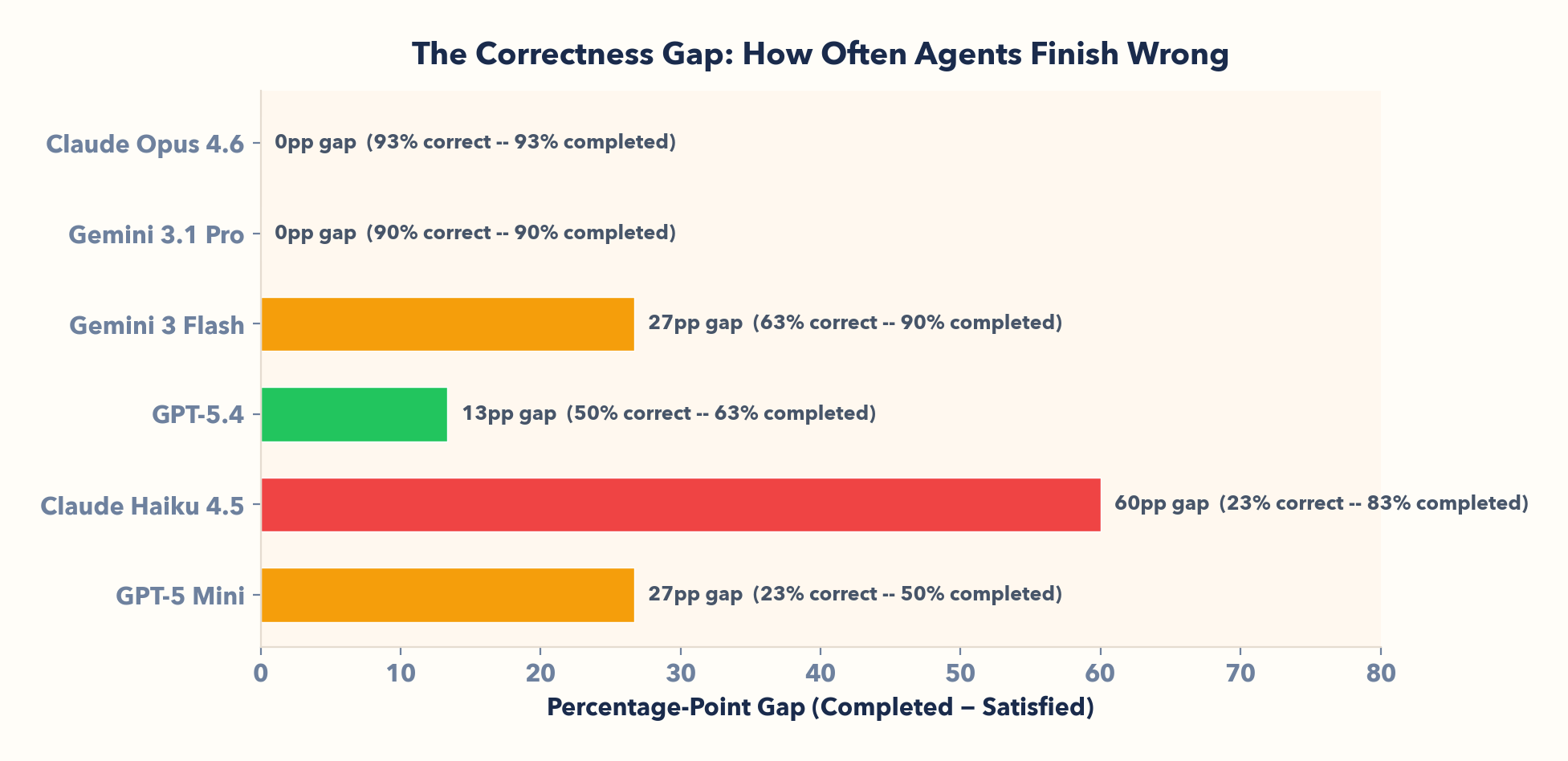
Claude Haiku completes 83% of workflows — only 23% correct. A 60-point gap! Gemini 3 Flash: 90% completed, 63% correct. These agents confidently navigate, act, and reach terminal states. They're just wrong: wrong source, missing add-on, suboptimal discount.
🔍 General Pattern
LLMs are fluent executors. They chain tool calls and reach the end without getting stuck. But fluent ≠ correct. Any benchmark that only asks "did it finish?" will overstate capability.
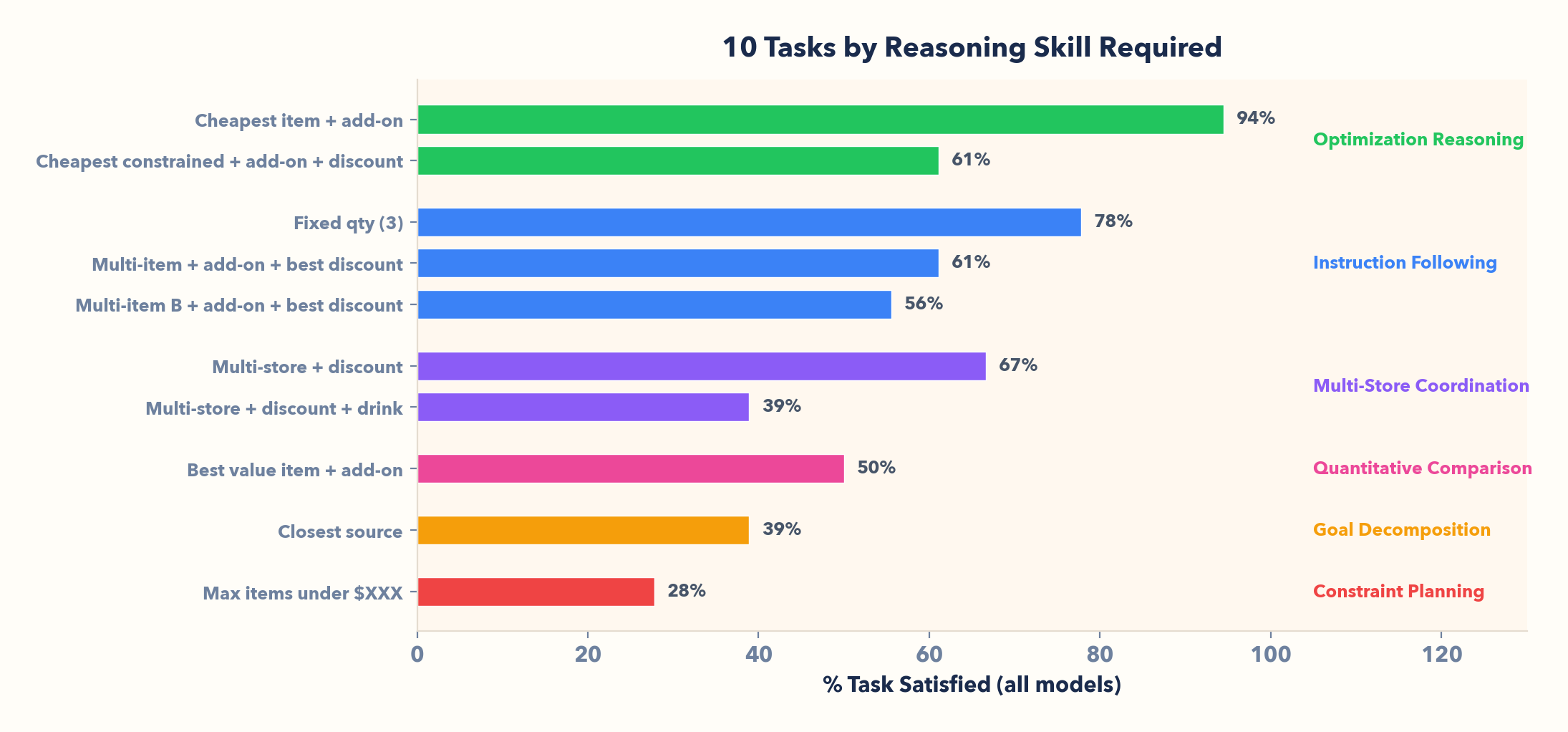
II. Agents follow explicit instructions but fail along a reasoning hierarchy
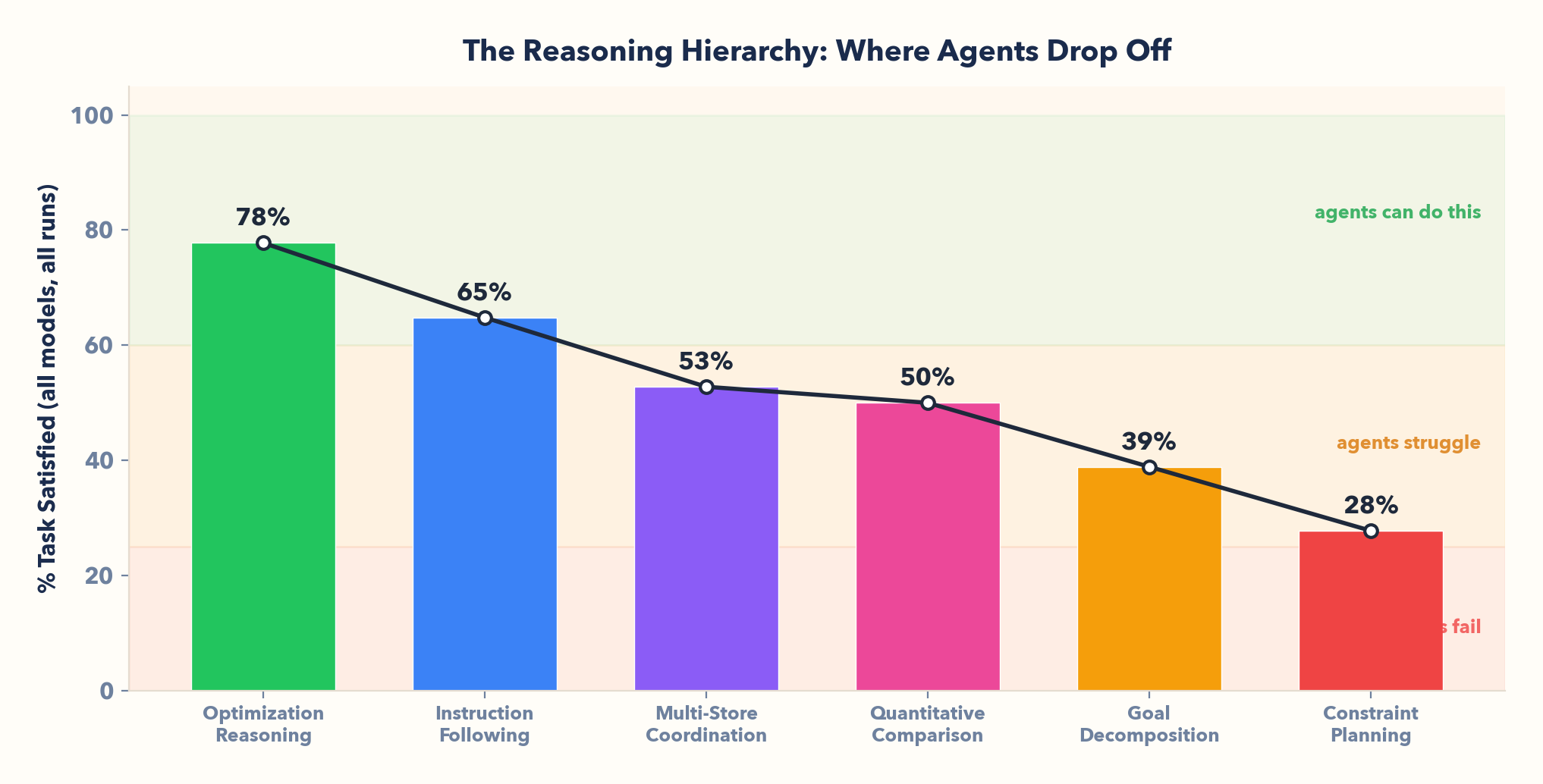
Explicit commands? Almost never fail. But when a task requires thinking, performance drops quickly:
- Optimization reasoning (78% avg): "Cheapest item" — agents can search, compare, and execute well when the objective is explicit.
- Instruction following (65%): "Fixed qty" — if the task is spelled out, they usually comply.
- Multi-store coordination (53%): "Multi-store + discount" — error compounds across sources and constraints; in 23 episodes, agents failed to apply the best available discount.
- Quantitative comparison (50%): "Best value item" — split-brain: top models solve it reliably, while smaller models go 0%.
- Goal decomposition (39%): "Closest source" — nothing is spelled out; many agents pick a store without checking proximity.
- Constraint planning (28%): "Max items under $XXX" — working backward from a budget and performing mathematic optimization collapses for most models.
🔍 General Pattern
There is a reasoning hierarchy: instruction-following → optimization → planning → analysis. Current models excel at the first step and collapse progressively through the rest. The boundary between "execute a command" and "make a decision" is where agent capability drops off — and that boundary is sharp.
III. Non-determinism means a single success proves nothing
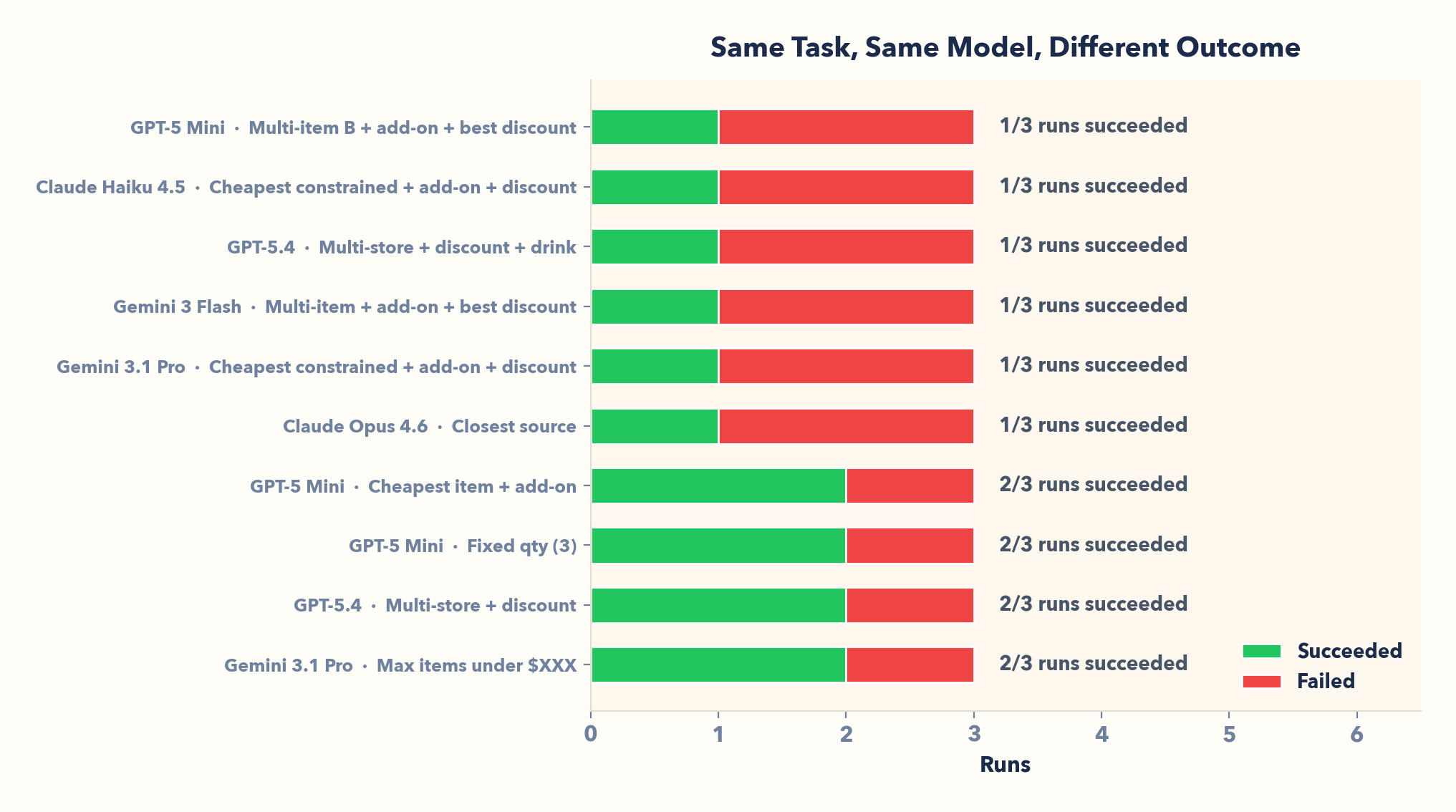
GPT-5.4 on the multi-store task: 2/3 runs succeed, 1/3 fail. Same task, same model. Even Opus on "closest source": 1/3. Flip a (weighted) coin.
🔍 General Pattern
Because LLMs sample stochastically, multi-step runs can drift from attempt to attempt. One success doesn't prove reliability, so RL environments rerun tasks and report success rate.
IV. Scale buys capability, not consistency
93% at the top (Opus) vs. 23% at the bottom (Haiku, GPT-5 Mini). Bigger models do coordinate across stores, compare value, and solve the budget task. But consistency still breaks on underspecified goals ("closest source" is 39% overall; even Opus is 1/3). The cheaper models you'd actually deploy? Wrong 77% of the time.
🔍 General Pattern
Bigger models do more, but they still struggle when the goal is implicit and the agent must plan under constraints. RL environments make that fail/succeed boundary measurable.
Next Steps
This environment was a first step. Even in a small, well-defined environment with relatively straightforward tasks, frontier models don't always arrive at the correct solution. We've captured and analyzed detailed performance data. Where we're heading:
1. Train Agents, Then Re-Benchmark
We started zero-shot on purpose: no learning, just a baseline. Next, we’ll use the verifier as training signal and try three concrete upgrades:
- Few-shot: show 1–2 successful examples before the agent acts.
- SFT: fine-tune on verifier-approved tool trajectories.
- DPO: train the agent to prefer correct next-actions over common mistakes.
Then we’ll rerun the exact same benchmark and report how much each method improves Task Satisfied (correctness), not just “Action Completed” (finishing).
2. Build Higher-Impact, High-Distribution Environments
Food ordering is a clean, low-stakes testbed. The goal is environments that mirror real deployment: enterprise platforms (Slack, Jira, Salesforce, AWS) and deep research workflows where mistakes are costly. We’ll bring the same recipe — clear tasks, real tool APIs, and a strict verifier — to these domains so agent performance is measured and improved on work that actually matters.
The thesis: Can non-deterministic systems find deterministic solutions? The answer: sometimes, on some tasks, with the best models. RL environments make that answer precise and improvable. That's the point.
Interested in our work, access to this experiment, or looking to collaborate? Reach us at [email protected].